Un datasets, o conjunto de datos, es simplemente una colección de datos.
El formato más simple y común para los conjuntos de datos que encontrará en línea es una hoja de cálculo o formato CSV: un solo archivo organizado como una tabla de filas y columnas. Pero algunos conjuntos de datos se almacenarán en otros formatos y no tienen que ser solo un archivo. A veces, un conjunto de datos puede ser un archivo zip o una carpeta que contiene varias tablas de datos con datos relacionados.
¿Cómo se crean los conjuntos de datos?
Los diferentes conjuntos de datos se crean de diferentes maneras. En esta publicación, encontrará enlaces a fuentes con todo tipo de conjuntos de datos. Algunos de ellos serán datos generados por máquinas. Algunos serán datos recopilados a través de encuestas.
Algunos pueden ser datos registrados a partir de observaciones humanas. Algunos pueden ser datos extraídos de sitios web o extraídos a través de API.
Siempre que trabaje con un conjunto de datos, es importante tener en cuenta: ¿cómo se creó este conjunto de datos? ¿De dónde provienen los datos? No salte directamente al análisis; tómese el tiempo para comprender primero los datos con los que está trabajando.
Los datasets son importantes porque permiten acceder a información clara y ordenada. A nivel de aprendizaje, proporcionan un medio ideal para realizar pruebas o poner en practica lo aprendido con información del mundo real.
En esta publicación te traemos distintos datasets que son públicos y te permitirán trabajar con ellos y poner en practica tus conocimientos.
Te puede interesar también:
- Curso gratis: Conviértete en un experto en gestión de proyectos

- Aprende Scrum desde cero y certifícate gratis como Scrum Foundation Professional
- ¿Aún no sabes programar? Este curso gratuito de Python te enseñará


Colección del Museo de Arte Moderno (MoMA)
La Colección del Museo de Arte Moderno incluye metadatos sobre todo tipo de expresiones visuales como la pintura, la arquitectura o el diseño. Contiene más de 130.000 registros y tiene información de cada obra incluyendo el título, artista, dimensiones, etc.
La colección incluye dos conjuntos de datos: ‘Artista’ y ‘Obra de arte’ disponibles en formatos CSV y JSON. Los datos se pueden bifurcar o descargar directamente desde la página de GitHub. Sin embargo, el conjunto de datos tiene información incompleta y solo debe usarse con fines de investigación. Es por eso que es el candidato perfecto, ya que se asemeja a un escenario del mundo real donde a menudo faltan datos.
Para empezar, podemos explorar el conjunto de datos de artistas.
SELECT nationality, COUNT(nationality) as "Number of Artists"
FROM artists
GROUP BY nationality
ORDER BY COUNT(nationality) DESC LIMIT 10
Estoy agrupando a los artistas por su nacionalidad y limitando los resultados a los 10 países principales. Al configurar la opción “Gráfico” en Arctype Environment, obtenemos un gráfico de barras vertical que se ve así:
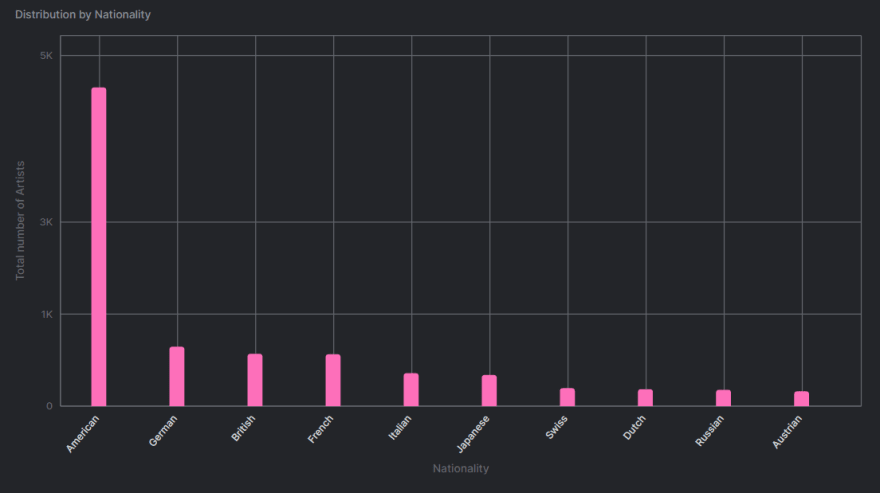
Este es un ejemplo trivial para comenzar con el conjunto de datos. Puede hacer mucho con SQL y visualización de datos con la ayuda de Arctype. Por ejemplo, agrupar por género con la ayuda del campo “género” y el análisis de series temporales de obras de arte de los atributos “start_date” y “end_date” .
Tenga en cuenta que, debido a su gran tamaño, el conjunto de datos se versiona con la extensión Git Large File Storage (LFS) . Para hacer uso de los datos, la extensión LFS es un requisito previo.
¡Pero no te preocupes! Si está buscando un conjunto de datos relativamente más pequeño para comenzar de inmediato, el siguiente estará en su lista.
Conjunto de datos de Covid
El conjunto de datos de Covid-19 es una serie de datos de tiempo basada en los casos diarios informados en los Estados Unidos. Se obtiene de los archivos publicados por el New York Times. La colección contiene datos históricos y en vivo que se actualizan con frecuencia. Los datos se subdividen nuevamente en 57 estados y más de 3000 condados.
Además de las columnas presentes en el conjunto de datos históricos, los archivos en vivo también registran lo siguiente:
- casos: El número total de casos, incluidos los casos confirmados y probables.
- muertes: el número total de muertes, incluidas las muertes confirmadas y probables.
- casos_confirmados: Solo casos confirmados por laboratorio.
- confirmed_deaths: Solo muertes confirmadas por laboratorio.
- probable_cases: el número de casos probables únicamente.
- probable_deaths: el número de muertes probables solamente.
Pero, ¿por qué utilizar la recopilación de datos en vivo si cambia constantemente y es propensa a inconsistencias? Porque así es como se ve un escenario del mundo real. No siempre se puede tener toda la información sobre cada atributo. Es por eso que este conjunto de datos le sirve bien.
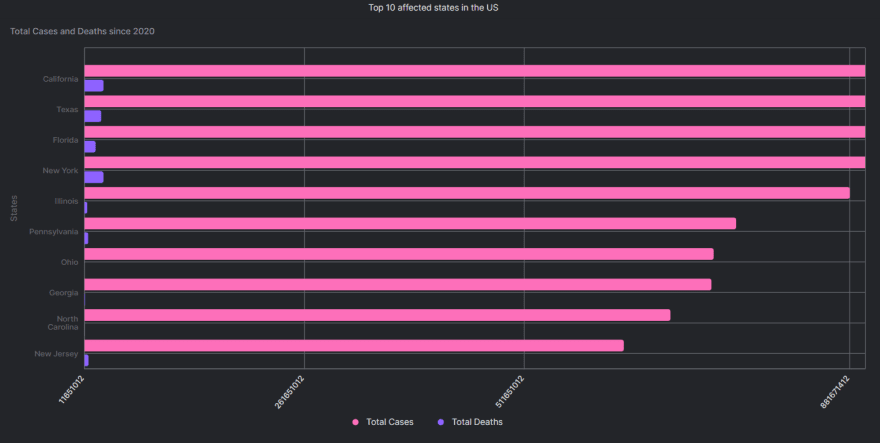
Para empezar, podemos averiguar cuáles son los estados más afectados del país.
SELECT
SUM(cases) as 'Total Cases',
state as 'State',
SUM(deaths) as 'Total Deaths'
FROM us_states
GROUP BY state
ORDER BY SUM(cases) DESC
LIMIT 10
Estoy limitando mi resultado a los 10 estados principales, puede elegir más modificando el comando ‘LIMIT’ .
Si está familiarizado con Arctype Environment, notará que le da la opción de seleccionar un ‘Gráfico’ cuando una consulta se ejecuta con éxito. Elegí la opción ‘Gráfico de barras horizontales’ con:
- Eje X: casos totales, muertes totales
- Eje Y: Estado
Después de agregar el ‘Título’ usando la opción ‘Configurar gráfico’ , mi resultado final se ve así:
¿Qué tal si intentas las siguientes consultas tú mismo?
- Trazando la tendencia de -Casos confirmadosMuertes confirmadas
- Los condados más afectados en los estados más afectados
Conjunto de datos de películas de IMDB
El siguiente conjunto de datos en la lista es una colección de scripts de Ruby y Shell que extraen datos del sitio web de IMDB y los exportan a un archivo CSV con un formato agradable. Yo, ahora, tengo una excusa de por qué algunas referencias de películas viven en mi cabeza sin pagar alquiler.
Pero, ¿por qué necesita estos scripts si IMDB ya pone todos los datos a disposición de los clientes? Bueno, los conjuntos de datos de IMDB están sin procesar y se subdividen en varios archivos de texto. Los scripts de Ruby almacenan toda esta información en un solo archivo CSV, lo que facilita su análisis. El enfoque también garantiza que tengamos acceso a los datos más recientes con campos como:
- Título
- Año
- Presupuesto
- Largo
- Clasificación
- Votos
- Distribución de votos
- Clasificación de la MPAA
- Género
Pero espera, los beneficios no acaban aquí. Para facilitarle la vida, la página de GitHub también proporciona un script SQL para definir esta tabla con los campos mencionados anteriormente.
Duración de la luz solar por ciudad
El conjunto de datos de duración de la luz solar está inspirado en la lista dinámica de ciudades ordenadas por la duración de la luz solar recibida en horas al año. Esta extensa lista contiene los datos de 381 ciudades de 139 países y nuevamente está subdividida por meses.
Pero, ¿por qué debería importarnos cuánta luz solar recibe una ciudad? Porque la ‘hora de sol’ es un indicador climatológico que puede ayudarnos a medir patrones y cambios para un lugar particular de la Tierra.
Dado que los datos provienen de Wikipedia y cambian constantemente, están lejos de estar completos. Pero lo mismo también lo convierte en un conjunto de datos realista para ensuciarse las manos.
Por ejemplo, con la ayuda del conjunto de datos Country to Continent, podemos agrupar las ciudades por continente y visualizar el patrón en diferentes ubicaciones geográficas.
Volviendo a nuestra discusión sobre la comida, el siguiente conjunto de datos merece una pequeña introducción.
Cambios en el precio de los cereales
El conjunto de datos de precios de cereales contiene información sobre los precios del trigo, el arroz y el maíz durante tres décadas. Desde febrero de 1992 hasta enero de 2022, este conjunto de datos se actualiza todos los meses.
Pero eso no es todo. Lo que hace que este conjunto de datos sea aún más especial es que tiene en cuenta la tasa de inflación que muchos de nosotros olvidamos al visualizar datos de series temporales. Cada fila en el conjunto de datos tiene los siguientes campos:
- Año
- Mes
- Precio del trigo por tonelada
- Precio del arroz por tonelada
- Precio del maíz por tonelada
- Tasa de inflación
- Precio moderno del trigo por tonelada (después de tener en cuenta la inflación)
- Precio moderno del arroz por tonelada
- Precio moderno del maíz por tonelada
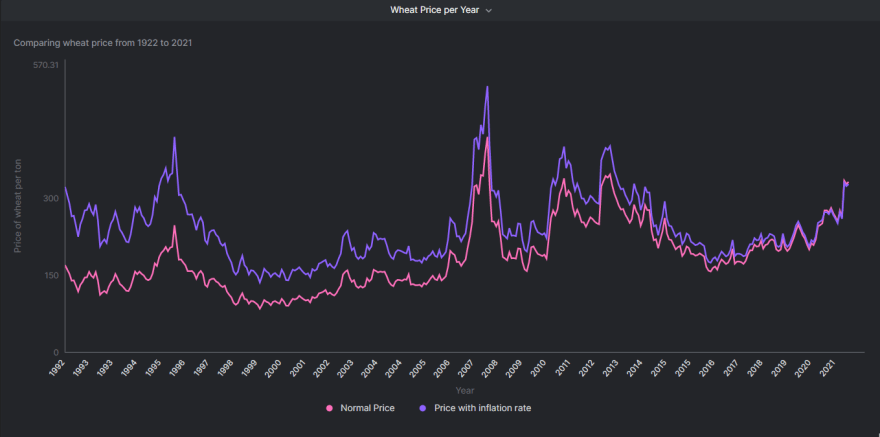
Mirando el conjunto de datos, lo primero que mi cerebro analítico quiere explorar es el patrón de precios con el tiempo. Vamos a hacer eso. Comenzaré con los precios del trigo excluyendo el año actual (2022) porque no tenemos datos completos para eso.
Mi consulta SQL se parece a –
SELECT
year,
price_wheat_ton AS 'Normal Price',
price_wheat_ton_infl AS 'Price with inflation rate'
FROM rice_wheat_corn_prices
WHERE year!=2022
Para visualizar los resultados, estoy trazando un ‘Gráfico de líneas’ usando la opción ‘Gráfico’ de Arctype . Los campos para el eje X y el eje Y son los siguientes:
- Eje X: Año
- Eje Y: Precio normal, Precio con tasa de inflación
Mi gráfico final se ve así:
Avanzar. Experimente también con los precios del arroz y el maíz.
Si encuentra útil este conjunto de datos, ¿qué le parece si consulta uno similar sobre Precios del café, el arroz y la carne de vacuno del mismo autor?
Deja tus comentarios y sugerencias
Sobre Facialix
Facialix es un sitio web que tiene como objetivo apoyar en el aprendizaje y educación de jóvenes y grandes. Buscando y categorizando recursos educativos gratuitos de internet, de esta manera Facialix ayuda en el constante aprendizaje de todos.


